您好,欢迎光临某某户外篷房有限公司!
语言选择:
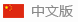


AI 画的玛丽莲 · 梦露,倒转 180 ° 后,竟然变成了爱因斯坦?!

这是最近在社交媒体上爆火的扩散模型视错觉画,随便给 AI 两组不同的提示词,它都能给你画出来!
哪怕是截然不同的对象也可以,例如一位男子,经过反色处理,就神奇地转变成一名女子:

就连单词也能被翻转出新效果,happy 和 holiday 只在一旋转间:
原来,这是来自密歇根大学的一项 " 视觉字谜 " 新研究,论文一发出就在 Hacker News 上爆火,热度飙至近 800。

英伟达高级 AI 科学家 Jim Fan 赞叹称:
这是我近期见到最酷的扩散模型!

还有网友感叹称:
这让我想到了从事分形压缩工作的那段经历。我一直认为它是纯粹的艺术。

要知道,创作一幅经过旋转、反色或变形后呈现出新主题的绘画作品,怎么也需要画家对色彩、形状、空间具备一定的理解能力。
如今连 AI 也能画出这样的效果,究竟是如何实现的?实际效果是否有这么好?
我们上手试玩了一番,也探究了一下背后的原理。
Colab 就能直接试玩
我们用这个模型绘制了一组 Lowpoly 风格的画,让它正着看是一座山,反过来则是城市的天际线。

同时,我们让 ChatGPT(DALL · E-3)也试着画了一下,结果除了清晰度高一些之外似乎就没什么优势了。

而作者自己展示的效果则更加丰富,也更为精彩。
一座雪后的山峰,旋转 90 度就变成了一匹马;一张餐桌换个角度就成了瀑布……

最精彩的还要属下面这张图——从上下左右四个角度看,每个方向的内容都不一样。
(这里先考验一下各位读者,你能看出这四种动物分别是什么吗?)

以兔子为初始状态,每逆时针旋转 90 度,看到的依次是鸟、长颈鹿和泰迪熊。

而下面这两张图虽然没做到四个方向每个都有 " 新内容 ",但还是做出了三个不同的方向。

除了旋转,它还可以把图像切割成拼图,然后重组成新的内容,甚至是直接分解到像素级。

风格也是千变万化,水彩、油画、水墨、线稿……应有尽有。

那么这个模型去哪里能玩呢?
为了能让更多网友体验到这个新玩具,作者准备了一份 Colab 笔记。
不过免费版 Colab 的 T4 不太能带动,V100 偶尔也会显存超限,要用 A100 才能稳定运行。

甚至作者自己也说,如果谁发现免费版能带动了,请马上告诉他。

言归正传,第一行代码运行后会让我们填写 Hugging Face 的令牌,并给出了获取地址。
同时还需要到 DeepFloyd 的项目页面中同意一个用户协议,才能继续后面的步骤。

准备工作完成后,依次运行这三个部分的代码完成环境部署。

需要注意的是,作者目前还没有给模型设计图形界面,效果的选择和提示词的修改需要我们手动调整代码。
作者在笔记中放了三种效果,想用哪个就取消注释(去掉那一行前面的井号),并把不用的删除或注释掉(加上井号)。

这里列出的三种效果不是全部,如果想用其他效果可以手动替换代码,具体支持的效果有这些:

修改好后要运行这行代码,然后提示词也是如法炮制:

修改好并运行后,就可以进入生成环节了,这里也可以对推理步数和指导强度进行修改。
需要注意的是,这里一定要先运行 image_64 函数生成小图,然后再用后面的 image 变成大图,否则会报错。

做个总结的话,我们体验后的一个感觉是,这个模型对提示词的要求还是比较高的。
作者也意识到了这一点,并给出了一些提示词技巧:

△机翻,仅供参考
那么,研究团队是如何实现这些效果的呢?
" 糅合 " 多视角图像噪声
首先来看看作者生成视错觉图像的关键原理。
为了让图像在不同视角下,能根据不同的提示词呈现出不同的画面效果,作者特意采用了 " 噪声平均 " 的方法,来进一步将两个视角的图像糅合在一起。
简单来说,扩散模型(DDPM)的核心,是通过训练模型将图像 " 打碎重组 ",基于 " 噪点图 " 来生成新图像:

所以,要想让图像在变换前后,能根据不同提示词生成不同图像,就需要对扩散模型的去噪过程进行改动。
简单来说,就是对原始图像和变换后的图像,同时用扩散模型进行 " 打碎 " 处理做成 " 噪点图 ",并在这个过程中将处理后的结果取平均,计算出一个新的 " 噪点图 "。

随后,基于这个新的 " 噪点图 " 生成的图像,就能在经过变换后呈现出想要的视觉效果。
当然,这个变换的图像处理过程,必须要是正交变换,也就是我们在展示效果中看到的旋转、变形、打碎重组或反色等操作。
具体到扩散模型的选择上,也有要求。
具体来说,这篇论文采用了DeepFloyd IF来实现视错觉图像生成。
DeepFloyd IF 是一个基于像素的扩散模型,相比其他扩散模型,它能直接在像素空间(而非潜在空间或其他中间表示)上进行操作。
这也让它能更好地处理图像的局部信息,尤其在生成低分辨率图像上有所帮助。
这样一来,就能让图像最终呈现出视错觉效果。
为了评估这种方法的效果,作者们基于 GPT-3.5 自己编写了一个 50 个图像变换对的数据集。
具体来说,他们让 GPT-3.5 随机生成一种图像风格(例如油画风、街头艺术风),然后再随机生成两组提示词(一个老人、一个雪山),并交给模型生成变换画。
这是一些随机变换生成的结果:

随后,他们也拿 CIFAR-10 进行了一下不同模型间图像生成的测试:

随后用 CLIP 评估了一下,结果显示变换后的效果和变换之前的质量一样好:

作者们也测试了一下,这个 AI 能经得起多少个图像块的 " 打碎重组 "。
事实证明,从 8 × 8 到 64 × 64,打碎重组的图像效果看起来都不错:

对于这一系列图像变换,有网友感叹 " 印象深刻 ",尤其是男人转变成女人的那个图像变换:
我看了大概有 10 遍左右。

还有网友已经想把它做成艺术作品挂在墙上了,或是使用电子墨水屏:

但也有专业的摄影师认为,现阶段 AI 生成的这些图像仍然不行:
仔细观察的话,会发现细节经不起推敲。敏锐的眼睛总是能分辨出糟糕的地方,但大众并不在意这些。

那么,你觉得 AI 生成的这一系列视错觉图像效果如何?还能用在哪些地方?
参考链接:
[ 1 ] https://news.ycombinator.com/item?id=38477259
[ 2 ] https://arxiv.org/pdf/2311.17919.pdf
[ 3 ] https://twitter.com/DrJimFan/status/1730253638935920738
Copyright © 2002-2022 球王会篷房帐篷销售站 版权所有 Powered by EyouCms 地址:广东省广州市番禺经济开发区 备案号:等ICP备98789998号 网站地图








